
Always feeling overwhelmed in the ever-evolving world of AI? Don’t worry, Llama 3 is redefining the landscape with groundbreaking features and unparalleled flexibility. Whether you’re a researcher, developer, or business leader, Llama 3 opens new doors for innovation—empowering you to create more human-like interactions, generate smarter insights, and push the boundaries of what’s possible in AI.
Ready to transform your next project?
Discover how Llama 3 is setting a new standard in the world of AI and language models.
Key takeaways
- Llama 3 is an advanced AI language model developed by Meta that provides advanced natural language processing, text generation, and text understanding. Its versatility makes it a powerful tool in many industries such as customer support, healthcare, and content creation.
- Llama 3 outperforms its predecessors with multilingual support for over 100 languages, improved text generation accuracy, and faster processing, making it ideal for complex language tasks.
- Llama 3 introduces untrained learning, allowing AI to handle tasks without explicit training, faster data processing, and enhanced contextual awareness for long-form content creation.
- This model offers advanced tuning capabilities, allowing users to tailor Llama 3 for specific tasks, such as healthcare or legal applications, ensuring highly accurate and specialized output.
- Meta emphasizes the responsible use of AI with features to reduce bias and increase transparency. Future versions of Llama will expand multimodal capabilities, scalability, and data efficiency, along with a focus on ethical AI advancements.
Overview of Llama

(Image Source: Meta)
Llama (Language Model Meta AI) is a family of advanced transformer-based language models developed by Meta (formerly Facebook). Llama is designed to push the boundaries of natural language understanding, enabling high-level tasks such as text generation, summarization, and comprehension. Its versatility makes it ideal for use cases in customer support, content creation, data analysis, and more.
Initially launched as a cutting-edge AI model, Llama has undergone several iterations, with each version offering significant improvements in terms of scalability, accuracy, and capabilities. The latest version, Llama 3, marks a major leap forward in AI-driven language processing.
The Evolution of Llama from Previous Versions
The journey of Llama from its first release to Llama 3 showcases continuous enhancements. Key improvements with each iteration include expanded training datasets, optimized algorithms, and better handling of complex linguistic structures. Llama 1 focused primarily on foundational AI tasks like text generation and summarization. Llama 2 expanded on this by improving contextual understanding and supporting larger-scale models.
Llama 3, the latest version, further enhances the model’s ability to process nuanced language tasks, making it faster and more precise than its predecessors. It includes refined transformer architecture, allowing it to understand and generate text in ways that are closer to human interaction.
Outstanding Features of Llama 3 Compared to Previous Versions
Llama 3 brings powerful tools to the table that push the boundaries of what AI can do today. These features enable creators and developers to generate synthetic data, fine-tune models for specialized tasks, and deploy solutions with unmatched efficiency.
| Feature | Description |
|---|---|
| Multilingual Support | Supports over 100 languages, enabling seamless language switching for global businesses to reach diverse markets. |
| Improved Accuracy | Offers higher accuracy in context comprehension and text generation, minimizing incoherent responses in long-form content. |
| Synthetic Data Generation | Generates synthetic data by creating new variations of existing content, enhancing versatility. |
| Fine-Tuning Capabilities | Customizable for specialized tasks, such as optimizing AI performance in specific fields like healthcare (e.g., LoRA). |
| RAG & Tool Use | Introduces zero-shot tool use and retrieval-augmented generation (RAG) to autonomously access external knowledge for problem-solving. |
Enhanced AI Capabilities of Llama 3
Llama 3 introduces cutting-edge features that make it stand out in the AI landscape:
- Zero-Shot Learning: Llama 3 is equipped with enhanced zero-shot learning capabilities, allowing the model to perform tasks it hasn’t been explicitly trained for, which boosts its utility across diverse applications.
- Faster Processing: With architectural improvements and better optimization techniques, Llama 3 can process inputs and deliver outputs faster than previous versions, ensuring high scalability for business applications.
- Contextual Awareness: Improved contextual understanding means Llama 3 can maintain coherence over longer passages of text, making it more reliable for complex writing tasks like research summaries or detailed reports.
How Llama 3 Works: A Deep Dive into Its Architecture and Training
Llama 3 is a powerful machine-learning model designed to handle natural language tasks. Here is a simple breakdown of how it works:
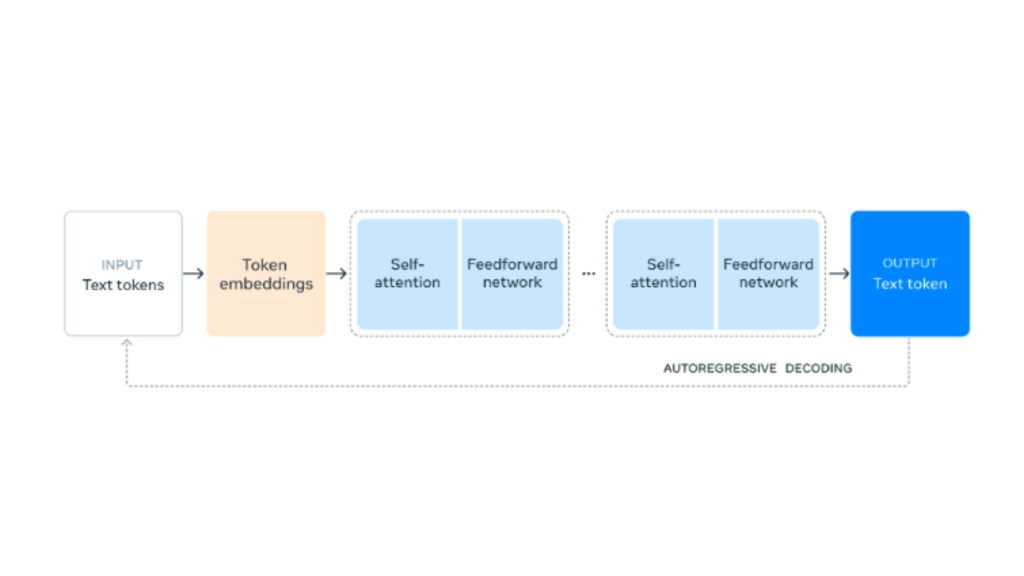
Architecture of Llama
Llama follows a transformer-based architecture, which has become a standard for most large-scale natural language processing (NLP) models. The transformer architecture allows for parallel processing of input data, making it faster and more scalable than earlier RNNs (Recurrent Neural Networks) or LSTMs (Long Short-Term Memory Networks).
(Image Source: Meta)
Key components
- Multi-Head Self-Attention Mechanism: This allows the model to focus on different parts of the input text at different layers, improving the contextual understanding of words in sentences.
- Feedforward Layers: These linear transformations help process the self-attention outputs and further refine the model’s ability to predict the next word or phrase.
- Positional Encoding: Since transformers do not process data sequentially, positional encodings are added to the input data to help the model understand the order of words in a sentence.
Training Process
Llama, like most large language models, is trained in two stages: pre-training and fine-tuning.
- Pre-Training: The model is exposed to a vast amount of unlabeled text data and learns to predict the next word in a sentence. This process helps the model develop a general understanding of language structure, grammar, and context.
- Fine-Tuning: After pre-training, the model can be fine-tuned on specific tasks, such as question answering, text summarization, or code generation. This is done by exposing the model to smaller, task-specific datasets, enabling it to specialize in certain applications.
Training Techniques
- Masked Language Modeling (MLM): Llama uses a technique where random tokens (words or sub-words) in the text are masked, and the model is trained to predict them. This helps it learn rich representations of words and context.
- Causal Language Modeling: During training, the model learns to predict the next word in a sequence, which is crucial for text generation tasks.
Data Preparation
The quality of a language model depends heavily on the data used during training. Llama is trained on a diverse and extensive dataset that includes various forms of textbooks, websites, academic papers, news articles, and more.
Data Preprocessing Steps
- Text Scraping: Text is collected from different sources, often including publicly available datasets like Common Crawl, Wikipedia, and academic databases.
- Data Cleaning: Before training, the data is cleaned to remove unnecessary characters, duplicates, and irrelevant information. This ensures that the model doesn’t learn from noisy or misleading data.
- Tokenization: Text data is tokenized into smaller units (words or subwords), which the model uses as input. Llama uses a byte-pair encoding (BPE) tokenizer to break down words into subword units.
Computational Requirements
Training a large model like Llama is computationally expensive. The computational requirements depend on the size of the model (e.g., number of parameters) and the amount of training data.
- Hardware: Llama is trained on high-performance GPUs (Graphics Processing Units) or TPUs (Tensor Processing Units), which provide the parallel computing power necessary for training transformers.
- Memory: Large models require substantial memory resources. Llama may use techniques like model parallelism (splitting the model across multiple GPUs) and data parallelism (training the model on different data batches in parallel) to manage these requirements.
- Training Time: Depending on the size of the model (ranging from smaller variants to those with hundreds of billions of parameters), training can take several weeks or even months.
Step-by-Step Guide to Using Llama 3
Initiating Llama 3.1 commences with an uncomplicated download and installation process. After installation, accessing the efficient language processing with pre-trained models is just a few clicks away.
Llama 3 is a powerful AI model designed to handle a wide range of tasks with precision and efficiency. Here’s a step-by-step guide to help you get started with Llama 3, from setting up the platform to deploying customized AI models.
Set Up Llama 3
To begin using Llama 3, you need to access the model through available platforms such as Hugging Face or by deploying it locally. Follow these steps:
- Set Up API Access: For cloud-based use, sign up for API access to Llama 3 through a service provider like OpenAI or Hugging Face, which enables you to integrate the model with your applications.
- Choose Your Environment: Decide whether you’ll be using Llama 3 in the cloud or on a local machine. Cloud options (such as Google Cloud or AWS) provide scalability, while local installations may require hardware with strong GPU support.
- Install Required Libraries: If you’re running it locally, install necessary machine learning libraries such as PyTorch, TensorFlow, or specific Llama 3 packages.
Load the Model
- Select the Model Size: Llama 3 comes in different sizes, such as 8B or larger models, depending on your needs. Larger models are better for more complex tasks, while smaller models offer faster responses.
- Load Pre-Trained Model: Use pre-trained weights if you want a quick start. For local deployments, download the model from the source and load it using your preferred machine-learning framework.
Input Your Query or Task
- You can start by selecting a pre-trained model (for example, a chatbot or summarizer) or by uploading a text file for the model to process.
- For text-to-text applications, input your query or request (e.g., “Summarize this article” or “Generate a marketing pitch”).
Adjust Fine-Tuning Options
- If available, explore fine-tuning options. This allows you to specify the context or tone of your output, which can be done using simple sliders or settings in the interface.
- Some tools let you adjust how creative or factual you want the generated response to be.
Generate Output
- After submitting your input, click “Run” or “Generate” to allow the Llama 3 model to process the data.
- The results will be displayed on the screen, and you can review them immediately.
Evaluate and Edit the Results
- Review the generated content. If necessary, adjust your input query or modify the fine-tuning settings to improve the results.
- Some platforms allow direct editing of the output for further refinement.
Export or Save the Results
- Once satisfied with the output, you can export the data. This could be a text file, PDF, or any other compatible format.
- Save your work within the platform for future reference or collaboration.
Utilize Integration Features
- Llama 3 typically integrates with various external platforms (such as Zapier, Google Drive, or Slack), so make sure to explore integration options to streamline workflows.
Integrating Llama 3 in Applications
Integrating Llama 3.1 into your applications opens new doors for efficient language processing. With a few adjustments, your apps can harness the power of advanced AI to deliver exceptional user experiences.
API Access for Seamless Integration
One of the key features of Llama 3 is its API access, which allows developers to integrate the AI model seamlessly into existing applications. This integration supports functions like natural language processing, content generation, and chatbot systems, simplifying the adoption of Llama 3 across various platforms.
APIs are crucial for providing real-time, scalable AI solutions without requiring major modifications to your existing tech stack.
Custom Fine-Tuning Capabilities
Llama 3 excels in its fine-tuning capabilities, which enable businesses to train the model with specific datasets. This allows for precise customization according to industry needs, such as healthcare, legal, or e-commerce sectors.
With better tools for quick adaptation, developers can fine-tune the Llama 3 model for enhanced performance in domain-specific applications, ensuring more accurate and relevant responses.
Cloud Deployment for Scalability
Cloud deployment is critical for businesses looking to integrate Llama 3 into large-scale operations. By deploying on cloud infrastructure, Llama 3 can scale up to manage extensive data processing and high user traffic, all without the need for significant investment in on-premise hardware. This is especially beneficial for applications requiring real-time data analysis and fast processing speeds.
Multilingual Support for Global Reach
Llama 3 offers multilingual support, enabling applications to handle text and dialogue in over 100 languages. This is crucial for businesses aiming to operate in multiple regions or engage global audiences.
Whether it’s customer service chatbots or multilingual content creation tools, Llama 3 ensures seamless communication across diverse markets, enhancing user experience and accessibility.
Integration with Analytics and Monitoring Tools
When integrating Llama 3 into applications, it’s essential to use analytics and monitoring tools. These tools provide insights into how well the AI is performing, tracking key metrics such as response time, user engagement, and accuracy. Continuous monitoring allows developers to fine-tune performance, ensuring that the AI remains optimized and responsive to evolving user needs.
Safety and Ethical Considerations
Exploring the use of Llama 3 demands a deep understanding of its safety features and ethical implications. Users should prioritize setting up responsible guidelines to prevent misuse and ensure that their applications respect privacy and data protection standards.
Responsibility & Safety Measures
Developers of Llama 3 prioritize responsible development and deployment, ensuring the technology adheres to safety measures like Llama Guard 2, Code Shield, and Cybersec Eval 2. These protocols perform rigorous risk assessments and vulnerability testing to prevent misuse and enhance security.
Furthermore, Llama 3 integrates a Responsible Use Guide (RUG) to guide ethical application development. This includes ongoing monitoring for fairness evaluation and bias reduction efforts.
The commitment extends to transparency in research documentation shared by Meta, highlighting their dedication to ethical guidelines that minimize biases while maximizing security and accountability in technological advancements.
Ethical Considerations and Limitations
Exploring the ethical considerations and limitations of Llama 3.1 involves addressing a range of challenges, from ensuring data integrity to upholding patient rights. The Responsible Use Guide provides essential resources aimed at fostering ethical development practices.
This guide underscores the need for careful curation of pretraining and fine-tuning data to minimize bias and maintain privacy concerns effectively.
Ethical decision-making is at the core of developing responsible AI technologies.
The subsequent section discusses enhanced features aimed at safeguarding cyber environments while defending younger users through innovative child safety protocols.
The Future of Llama AI Models
The future of Llama AI looks promising as AI technologies continue to advance at a rapid pace. Meta’s Llama series has already set a high standard with its current capabilities, but the upcoming iterations are expected to bring even more and refined features to meet evolving business needs and complex AI-driven tasks.
What’s Next for the Llama Series?
Future versions of the Llama AI series will focus on improving natural language understanding, enabling more human-like conversations and better handling complex inputs.
We can also expect expanded multimodal capabilities, allowing Llama to process text, images, and videos for more dynamic applications. With increased data efficiency, future iterations will require less training data while still delivering more accurate results.
Llama will also offer greater scalability and customization, empowering industries like healthcare and legal services to refine models more easily.
Finally, ethical AI will be a major focus, with efforts to reduce bias and increase transparency for the responsible and fair use of AI.
Conclusion
Llama is a powerful AI language model developed to enhance a range of applications, including content creation, natural language processing, and data-driven insights. With its enhanced multilingual support, improved accuracy, and powerful fine-tuning capabilities, Llama is transforming industries from healthcare to content marketing.
It’s important to approach AI integration carefully, ensuring that ethical considerations like data privacy and bias mitigation are prioritized to create positive and sustainable AI solutions.
Frequently Asked Questions
What is Llama and how does it work?
Llama is an AI language model that processes natural language inputs using deep learning to generate text-based outputs. It’s used across multiple industries for tasks like content creation and language translation.
How can Llama 3 be used in business applications?
Llama 3 is ideal for automating customer support, generating multilingual content, improving decision-making through data insights, and streamlining operations with AI-powered assistance.
What industries benefit most from using Llama 3?
Key industries benefiting from Llama 3 include healthcare, marketing, customer service, legal services, and education, where AI enhances productivity and decision-making.
What are the key features of Llama 3 compared to previous versions?
Llama 3 introduces advanced multilingual support, improved accuracy in text generation, synthetic data generation, and customizable fine-tuning options, making it more versatile than earlier versions.
How does Llama 3 ensure ethical AI usage?
Llama 3 prioritizes data privacy, minimizes biases in outputs, and supports transparent AI operations to ensure ethical usage across industries and applications.
